1. 编码器 - 解码器
1.1. 基本框架
class Encoder(nn.Module):
def __init__(self, **kwargs):
super(Encoder, self).__init__(**kwargs)
def forward(self, X, *args):
raise NotImplementedError # 占位符
class Decoder(nn.Module):
def __init__(self, **kwargs):
super(Decoder, self).__init__(**kwargs)
def init_state(self, enc_outputs, *args):
raise NotImplementedError
def forward(self, X, *args):
raise NotImplementedError # 占位符
class EncoderDecoder(nn.Module):
"""编码器-解码器架构的基类"""
def __init__(self, encoder, decoder, **kwargs):
super(EncoderDecoder, self).__init__(**kwargs)
self.encoder = encoder
self.decoder = decoder
def forward(self, enc_X, dec_X, *args):
enc_outputs = self.encoder(enc_X, *args)
# 编码器的输出最为解码器输入的一部分
dec_state = self.decoder.init_state(enc_outputs, *args)
return self.decoder(dec_X, dec_state)
1.2. seq2seq
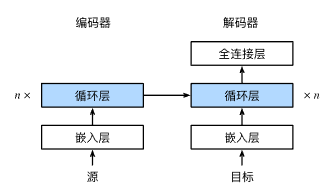
1.2.1. 编码器
- 将序列(时间步)的数字转换为张量
- 通过rnn输出上下文变量C,隐状态
class Seq2SeqEncoder(nn.Encoder):
def __init__(self, vocab_size, embed_size, num_hiddens, num_layers, dropout = 0, **kwargs):
super(Seq2SeqEncoder, self).__init__(**kwargs)
'''编码层
将数字编码为为向量
输入(batch_size, feature) 输出(batch_size, feature, embed_size)
'''
self.embeding = nn.Embedding(vocab_size, embed_size)
self.rnn = nn.gru(embed_size, nn_hiddens, num_layers, dropout = dropout)
def forward(self, X, *args):
# 输出'X'的形状:(batch_size,num_steps,embed_size)
X = self.embedding(X)
# 在循环神经网络模型中,第一个轴对应于时间步
X = X.permute(1, 0, 2)
# 如果未提及状态,则默认为0
output, state = self.rnn(X)
# output的形状:(num_steps,batch_size,num_hiddens)
# state的形状:(num_layers,batch_size,num_hiddens)
return output, state
1.2.2. 解码器
class Seq2SeqDecoder(nn.Decoder):
def __init__(self, vocab_size, embed_size, num_hiddens, num_layers,
dropout=0, **kwargs):
super(Seq2SeqDecoder, self).__init__(**kwargs)
self.embedding = nn.Embedding(vocab_size, embed_size)
self.rnn = nn.GRU(embed_size + num_hiddens, num_hiddens, num_layers,
dropout=dropout)
self.dense = nn.Linear(num_hiddens, vocab_size)
def init_state(self, enc_outputs, *args):
# 用隐状态来初始化上下文变量
return enc_outputs[1]
def forward(self, X, state):
X = self.embedding(X).permute(1, 0,2 )
# state[-1] 的维度为(layer_num , batch_size, num_hiddens)
context = state[-1].repeat(X.shape[0], 1, 1)
# 在feature上增加了元素C
X_and_c = torch.cat(X, context, 2)
output, state = self.rnn(X_and_context, state)
output = self.dense(output).permute(1, 0, 2)
return output , state
1.2.3. 训练过程
不同点:
- 定义使用MarkedSoftmaxCELoss 损失函数
- 塑造解码器输入,原序列前增加bos, 删除eos
相同点:
- apply(init(m)), optimizer , loss, net.train()
- 分epoch, 分批量,optimizer.zero_gred(), net(x) , l = loss(y_hat, Y), l.backward(), grad_clipping(net, theta), optimizer.step()
1.2.4. 预测过程
net.eval()
准备序列数据
对src编码,得到dec_state=context
传入一个
数据 dec_X 的维度为(1, 1)
Y 的维度为(1, 1, embed_size)
每一次更新dec_X, 更新了decodor的隐藏状态
def predict_seq2seq(net, src_sentence, src_vocab, tgt_vocab, num_steps,
device, save_attention_weights=False):
"""序列到序列模型的预测"""
# 在预测时将net设置为评估模式
net.eval()
'''
准备序列数据
'''
src_tokens = src_vocab[src_sentence.lower().split(' ')] + [
src_vocab['<eos>']]
enc_valid_len = torch.tensor([len(src_tokens)], device=device)
src_tokens = d2l.truncate_pad(src_tokens, num_steps, src_vocab['<pad>'])
# 添加批量轴
enc_X = torch.unsqueeze(
torch.tensor(src_tokens, dtype=torch.long, device=device), dim=0)
'''
对src编码,得到dec_state=context
'''
enc_outputs = net.encoder(enc_X, enc_valid_len)
dec_state = net.decoder.init_state(enc_outputs, enc_valid_len)
'''
传入一个<bos>数据
'''
dec_X = torch.unsqueeze(torch.tensor(
[tgt_vocab['<bos>']], dtype=torch.long, device=device), dim=0)
output_seq, attention_weight_seq = [], []
for _ in range(num_steps):
'''
dec_X 的维度为(1, 1), 每一次传入上一个时间步中预测出的值
Y 的维度为(1, 1, embed_size)
每一次更新dec_X, 更新了decodor的隐藏状态
'''
Y, dec_state = net.decoder(dec_X, dec_state)
# 我们使用具有预测最高可能性的词元,作为解码器在下一时间步的输入
dec_X = Y.argmax(dim=2)
pred = dec_X.squeeze(dim=0).type(torch.int32).item()
# 保存注意力权重(稍后讨论)
if save_attention_weights:
attention_weight_seq.append(net.decoder.attention_weights)
# 一旦序列结束词元被预测,输出序列的生成就完成了
if pred == tgt_vocab['<eos>']:
break
output_seq.append(pred)
return ' '.join(tgt_vocab.to_tokens(output_seq)), attention_weight_seq
这里可以优化使用束搜索
1.2.5. 损失函数
计算pred与label的Loss
计算序列的掩码
将loss与序列掩码相乘
class MaskedSoftmaxCELoss(nn.CrossEntropyLoss): """带遮蔽的softmax交叉熵损失函数""" # pred的形状:(batch_size,num_steps,vocab_size) # label的形状:(batch_size,num_steps) # valid_len的形状:(batch_size,) def forward(self, pred, label, valid_len): weights = torch.ones_like(label) weights = sequence_mask(weights, valid_len) # 掩码 self.reduction='none' unweighted_loss = super(MaskedSoftmaxCELoss, self).forward( pred.permute(0, 2, 1), label) weighted_loss = (unweighted_loss * weights).mean(dim=1) return weighted_loss
1.2.5.1. 掩码
- 生成序列掩码,可以使用arrange< valid_len获取
- 将所有掩码位置 置为0
def sequence_mask(X, valid_len, value=0):
"""在序列中屏蔽不相关的项"""
maxlen = X.size(1)
# 生成掩码
print(torch.arange((maxlen), dtype=torch.float32,
device=X.device)[None, :] )
print(valid_len[:,None])
'''
(none,:)是在dim = 0上创建一个=1 的维度
广播机制后mask = (batch_size, time_stem)
'''
mask = torch.arange((maxlen), dtype=torch.float32,
device=X.device)[None, :] < valid_len[:, None]
print(mask)
X[~mask] = value
return X
1.2.5.2. 预测序列评估
我们将BLEU定义为:
$$
\exp\left(\min\left(0, 1 - \frac{\mathrm{len}{\text{label}}}{\mathrm{len}{\text{pred}}}\right)\right) \prod_{n=1}^k p_n^{1/2^n},
$$
2. 注意力机制
查询值query, 键值对(key, value),每一个key 对应一个query
注意力权重计算的是query对key的关注程度,attention(query_num , key_num),每一行是当前查询对所有键的注意力,然后与query计算,得到每一个查询对query的注意力结果
$$
attention_weight = \alpha(query, key)\
f(x) = attention_weight * query
$$
2.1. 常见机制
2.1.1. 掩蔽注意力机制操作
对键值中不需要的部分掩蔽为0,具体操作是
- 将atterntion_weight(batch, query, key) 中的key维度数据通过掩码,转换为较小数
- 使用softMax,较小数转换为0,key对应此处的权重就是0了
def masked_softmax(X, valid_len):
'''
X:attention_weigth = (batch_size, query , key)
valid_len 不同批次掩蔽的长度,=(batch_size) 或 (batch_size, key)
'''
if valid_lens is None:
return nn.functional.softmax(X, dim=-1)
else:
shape = X.shape
if valid_lens.dim() == 1:
valid_lens = torch.repeat_interleave(valid_len, shape[1])
else:
valid_lens = valid_lens.reshape(-1)
'''
sequence_mash: 将param1中的第1维度按照 valid_lens的长度掩蔽,大于的掩蔽为values
'''
X = sequence_mask(X.reshape(-1, shape[-1]), valid_lens,values== -1e6)
return nn.functional.softmax(X.shape[shape], dim =-1) # 对掩蔽维度归一化
2.1.2. 加性注意力
键,查询有时是矢量(不同长度)转换为相同长度的矢量
$$
a(\mathbf q, \mathbf k) = \mathbf w_v^\top \text{tanh}(\mathbf W_q\mathbf q + \mathbf W_k \mathbf k) \in \mathbb{R}
$$
- 线性层操作,query=>(batch ,query, hidden_num),key=>(batch ,key hidden_num)
- 得到注意力矩阵,query=>(batch ,query,1 hidden_num),key=>(batch ,1,key hidden_num), query+key =>query=>(batch ,query,key, hidden_num)
- $W_t$ 是线性层(hidden_num, 1), 移除最后一个维度,得到attention_weight =(batch ,query,key,)
- 使用掩蔽注意力,对key上无用的权重屏蔽
class AddictiveAttention(nn.Module):
def __init__(self, key_size, query_size, num_hiddens, dropout, **kwargs):
super(AddictiveAttention, self).__init__(**kwargs)
self.W_k= nn.Linear(key_size, num_hiddens)
self.W_q = nn.Linear(query_size, num_hiddens)
self.W_v = nn.Linear(num_hiddens, 1)
self.dropout= nn.Dropout(dropout)
def forward(selk, query, key ,values, valid_lens):
query, key = W_q(query), W_k(key)
attention = query.unsquence(2) + key.unsquence(1)
attention = nn.tanh(attention)
attention = W_v(attention)
self.atterntion_weight = masked_softmax(attention, valid_lens)
return torch.bmm(self.attention_weight, values)
2.1.3. 点积注意力
计算效率高,但是要求query, key具有相同的张量长度,权重函数:
$$
a(\mathbf q, \mathbf k) = \mathbf{q}^\top \mathbf{k} /\sqrt{d}
$$
方差缩放,防止梯度消失
class DotProductAttention(nn.Module):
def __init__(self, dropout, **kwargs):
super(DotProductAttention, self).__init__(**kwargs)
self.dropout = nn.Dropout(dropout)
def forward(self, query, key,values, valid_lens):
# attention(batch_size, query_size, key_size)
attention = torch.bmm(query, key.transpose(1,2))/ math.sqrt(d)
self.attention_weight = masked_softmax(attention, valid_len)
# 输出(batch_size, query_size, feature_size)
return torch.bmm(self.dropout(self.attention_weight), values)
2.1.4. 多头注意力
使用多个结构一样,参数不一样的注意力去学习不同的知识

将键值对分为多个子空间,每个注意力机制学习一个子空间的特征,得到H组的注意力权重,然后将注意力权重通过线性层汇聚
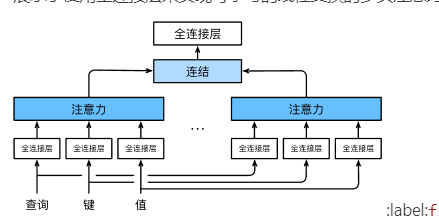
常规思路:
- 将query, key, values映射到子空间,使用不同的Linear映射
- 将不同头的注意力结果合并在一起,在feature维度上合并
- 再通过一个Linear线性层,连接所有head
并行思路
- 将query,key, values映射到完整空间,然后将完整空间查分成子空间,head与batch组成一个伪batch
- 再将子空间的数据通过点积注意力
- 将head从batch中分离出来,与feature合并,效果与非并行情况相同
- 最后通过线性层
class MultiHeadAttention(nn.Module):
def __init__(self, key_size, query_size, value_size, num_hiddens, num_head, dropout, bias = false, **kwargs):
self.num_head = head
self.attention = d2l.DotProductAttention(dropout)
self.W_k = nn.Linear(key_size, num_hiddens)
self.W_q = nn.Linear(query_size, num_hiddens)
self.W_v = nn.Linear(value_size, num_hiddens)
self.W_o = nn.Linear(num_hiddens, num_hiddens) # 全连接层
def forward(self, query ,key ,values, valid_lens):
# 转换为(batch_size* head, key/query , num_hidden/head)
query = transpose(self.W_q(query), self.head_num)
keys = transpose_qkv(self.W_k(keys), self.num_heads)
values = transpose_qkv(self.W_v(values), self.num_heads)
# 将掩码扩展为batch*head
if valid_len is not None:
valid_lens = torch.repeat_interleave(
valid_lens, repeats = self.num_heads , dim =0)
output = self.attention(query, key ,value, valid_len)
output_concat=transpose_output(output, self.num_heads)
return self.W_o(output_concat)
3. 附录
3.1. BLEU
def bleu(pred_seq, label_seq, k): #@save
"""计算BLEU"""
pred_tokens, label_tokens = pred_seq.split(' '), label_seq.split(' ')
len_pred, len_label = len(pred_tokens), len(label_tokens)
score = math.exp(min(0, 1 - len_label / len_pred))
for n in range(1, k + 1):
num_matches, label_subs = 0, collections.defaultdict(int)
for i in range(len_label - n + 1):
label_subs[' '.join(label_tokens[i: i + n])] += 1
for i in range(len_pred - n + 1):
if label_subs[' '.join(pred_tokens[i: i + n])] > 0:
num_matches += 1
label_subs[' '.join(pred_tokens[i: i + n])] -= 1
score *= math.pow(num_matches / (len_pred - n + 1), math.pow(0.5, n))
return score



