1. 大模型
训练流程

1.1. 预训练
无监督学习,学习先验的背景知识
大模型的输出总的概率与原数据比较,不需要 L(u) = ∑ilog (p(ui|u0,...,ui − 1)|θ)
数据获取
- 网页爬取,数据没有处理
- 重复
- 拼写错误
数据清洗
转换文本格式
去重
- URL爬取的网站去重
- 文档的相似度
- 对文档分组30M, 超过6次重复, 删除其余5行
- 启发式过滤,使用token级的KL散度去重
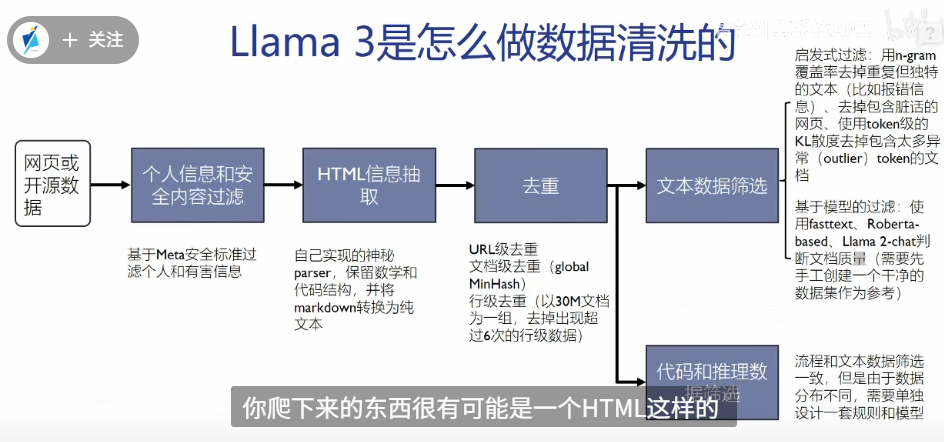
数据打包 1.
2. 一行一行的训练,而不是一句一句的训练 观测模型,使用测试集对中间模型测试
数据比例,代码模型中平衡代码补全(中间填充)与代码编写(从前向后编写)的任务,两种数据集都需要
1.1.1. 继续预训练
当前的base model 对于专业领域的效果很差,继续与训练补全知识。
加入新的数据,调整学习率
- warmup 的步数不会影响最终的结果
- 学习率较大,下游任务更好
- 对原有模型继续warmup,效果更差
使用梯形的学习率,保存拐点位置的学习率,继续预训练时候,使用拐点数据预训练,保持较高的搜索速度,拟合新增的数据集
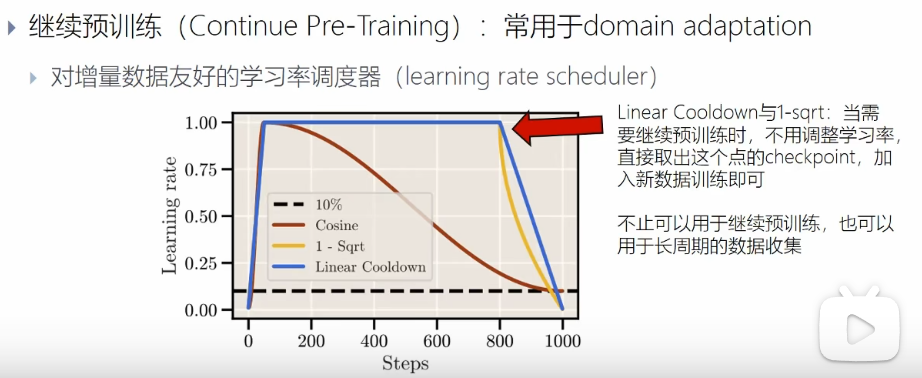
1.1.2. scaling up
扩大模型的参数和容量
1.1.3. 尺度定律
模型的损失是可预测的,与模型的算力,大小,数据集有较大的关系
- 模型的参数
- 数据的大小
- 算力
模型与参数、大小、算力由直接的关系,不需要训练,就能知道最终的训练结果
1.1.3.1. 尺度定律
模型与参数、大小、算力由直接的关系,与模型形状弱依赖
- 某个网络的占比
- 隐层数量的占比
- 每个head的大小
的影响很小,不需要对此调参
其他变量充足的时候,我们就知道模型最后的效果
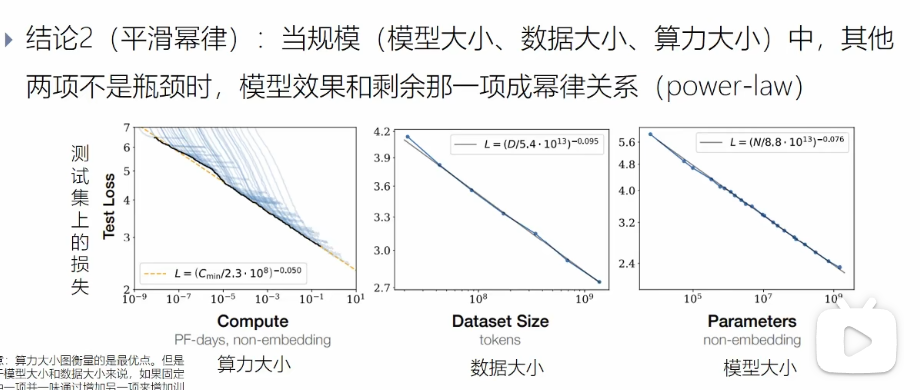
过拟合的普遍性,一味增加其中一项,模型效果就会进入衰退阶段

同等算力下,调整模型大小和数据集的大小
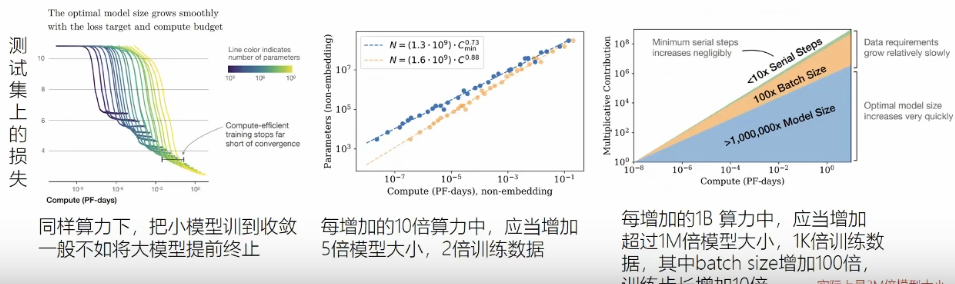
模型在训练集与测试集上表现高度相关
训练数据有显示,仍然可以重复使用数据进行训练得到可预测的“尺度定律”
其他模型(包括transform)都具有尺度定律
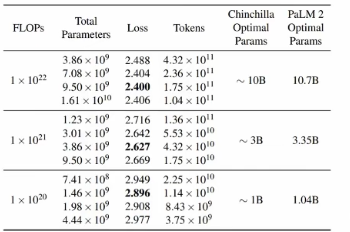
1.1.3.2. 利用尺度定律
固定模型的大小,更改预训练的数据量
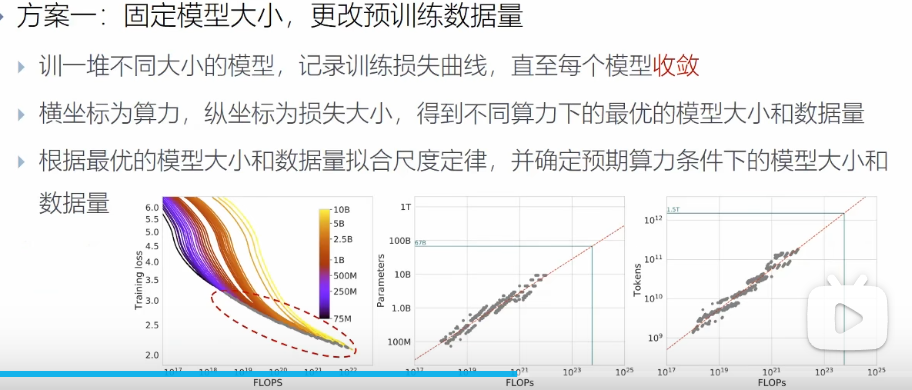
规定算力大小,训练不同大小的模型,(训练到模型收敛较难,可以得到算力的大小)
1.1.4. 涌现
大模型在训练数量的规模时,准确率会发生突变
1.2. 后训练
对齐人类的要求,回答问题有用、无害
1.2.1. 指令微调

上下文学习
- 用户给出例子,模型不更新参数直接学习
使用例子训练,模型直接输出
预训练-微调
- 在目标任务上进行微调
给出命令前缀,然后训练
指令微调
- 在非目标任务上进行泛化,在任务上泛化很好
指令-回答, 对回答的预测计算损失函数
1.2.2. 数据合成
- 人工构建任务例子
- 使用强模型根据种子任务生成指令
- 将生成的指令再给另一个强模型,获得指令的回答,得到<指令,回答> 对
1.2.3. test scaling
模型输出多个结果,打分选择结果
过程奖励模型>结果奖励模型
选择框架

1.2.4. 微调方法
1.2.4.1. lora
增加低秩矩阵
1.2.4.2. 前缀调整
训练的模型权重不再调整,k,v前分别添加可训练的连续前缀向量
冻结原权重,增加可训练模块
1.2.4.3. 提示调整
训练文本前增加提示命令
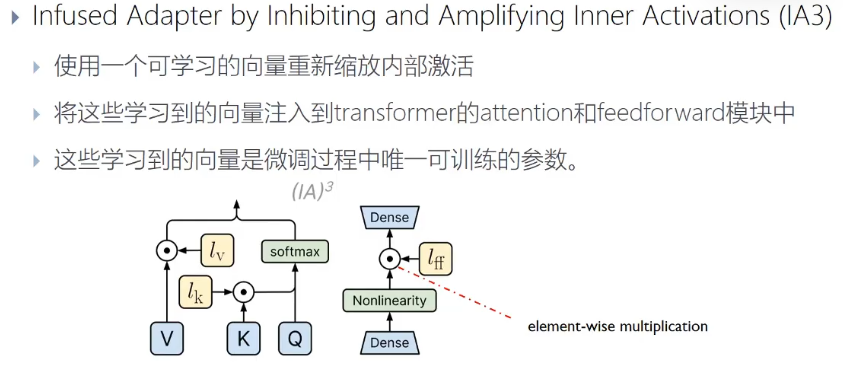
1.2.4.4. adapter
在前馈神经网络前增加低秩矩阵
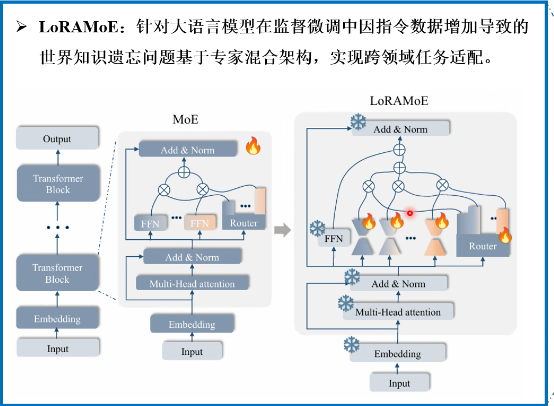
1.2.4.5. LoRAMoE
微调插入专家模型中的LoRA适配器
1.3. 强化学习
最大化智能体获得的期望累计奖励
1.3.1. PPO函数
策略: 大模型生成句子的过程π
轨迹: 一系列的动作,大模型生成句子时候,的状态与动作 τ = s1, a1, ..sn, an 奖励:R(τ),一整条轨迹的奖励
基于策略的强化学习的目标:找到一种策略,是在这个策略的轨迹上的奖励分数最大 $$ \begin{align} \underset{\pi_\theta}{argmax} j({\pi_\theta}) &= \underset{\pi_\theta}{argmax}E_{\tau~\pi}|R(\tau)|\\ & = \sum_\tau R(\tau)P(\tau|\pi_\theta) \end{align} $$ LOSS函数的梯度: $$ \begin{align*} \nabla J(\pi_\theta) &= \sum_\tau R(\tau) \nabla P(\tau|\pi_\theta) \\ &= \sum_\tau R(\tau) P(\tau|\pi_\theta) \frac{\nabla P(\tau|\pi_\theta)}{P(\tau|\pi_\theta)} \\ &= \sum_\tau R(\tau) P(\tau|\pi_\theta) \nabla \log(P(\tau|\pi_\theta)) \\ &= \mathbb{E}_{\tau \sim \pi_\theta} [R(\tau) \nabla \log(P(\tau|\pi_\theta))] \end{align*} $$ 路径的概率,从s0递推,推到T-1,计算出T的概率 $$ P(\tau|\pi_\theta) = \rho_0(s_0) \prod_{t=0}^{T-1} P(s_{t+1}|s_t, a_t)\pi_\theta(a_t|s_t) $$
$$ \nabla \log\left(P(\tau|\pi_\theta)\right) = \nabla \left[ \log \rho_0(s_0) + \sum_{t=0}^{T-1} \log P(s_{t+1}|s_t, a_t) + \sum_{t=0}^{T-1} \log \pi_\theta(a_t|s_t) \right] $$
前两项和策略模型的参数 θ 无关,可舍去。于是 $$ \nabla \log\left(P(\tau|\pi_\theta)\right) = \sum_{t=0}^{T-1} \nabla \log \pi_\theta(a_t|s_t) $$ 带入Loss的梯度中,使用每时刻的奖励函数代替总路径R(τ) $$ \nabla J(\pi_\theta) = \mathbb{E}_{\tau \sim \pi_\theta}\left[ \sum_{t=0}^{T-1} \Psi_t \nabla \log \pi_\theta(a_t|s_t) \right] $$ ψt的组成形式
- $\sum_{t=0}^\infty r_t$
轨迹的累积奖励
- $\sum_{t'=t}^\infty \gamma^{t'-t}
r_{t'}$ 轨迹的折扣奖励
- $\sum_{t'=t}^\infty \gamma^{t'-t} r_{t'} -
b(s_t)$ 引入基线
- Qπ(st,at)
动作价值函数
- Aπ(st,at)
优势函数
- rt + Vπ(st + 1) − Vπ(st) 时序差分残差
累计折扣奖励 Gt = rt + γrt + 1 + γ2rt + 2 + … + γT − t − 1rT − 1 = rt + γGt + 1
动作价值函数:在策略π 下,从状态 s_t 开始并执行动作 a_t 后,未来所有折扣奖励的期望。 $$ \begin{align} Q_\pi(s_t, a_t) &= \mathbb{E}_\pi[G_t | s_t, a_t] \\ &= \mathbb{E}_\pi\left[\sum_{t=0}^{T-t} \gamma^{t'} r_{t'} | s_t, a_t\right] \\ &= \mathbb{E}_\pi[r_t | s_t, a_t] + \mathbb{E}_\pi[\gamma V_\pi(S_{t+1}) | s_t, a_t] \\ &= \sum_{s_{t+1} \in \mathcal{S}} P(s_{t+1}|s_t, a_t)R(s_t, a_t, s_{t+1}) + \gamma \sum_{s_{t+1} \in \mathcal{S}} P(s_{t+1}|s_t, a_t)V_\pi(s_{t+1}) \\ & 贝尔曼期望方程,将 G_t 拆分为当前奖励和未来价值\\ &= \mathbb{E}_{s_{t+1} \sim P(\cdot|s_t, a_t)}[r + \gamma V_\pi(s_{t+1})] \end{align} $$ 优势函数:在策略 ππ 下,在状态 s_t 执行动作 a_t 相对于在该状态下平均(期望)价值的“优势”或“额外价值”。 $$ \begin{align} A_\pi(s_t, a_t) &= Q_\pi(s_t, a_t) - V_\pi(s_t) \\ &= \mathbb{E}_{s_{t+1} \sim P(\cdot|s_t, a_t)}[r_t + \gamma V_\pi(s_{t+1})] - \mathbb{E}_{s_{t+1} \sim P(\cdot|s_t, a_t)}[V_\pi(s_t)] \\ &= \mathbb{E}_{s_{t+1} \sim P(\cdot|s_t, a_t)}[r_t + \gamma V_\pi(s_{t+1}) - V_\pi(s_t)] \\ &= \mathbb{E}_{s_{t+1} \sim P(\cdot|s_t, a_t)}[\text{TD\_error}] \end{align} $$
1.3.2. 价值损失
这里提到的“价值训练过程”通常指的是在强化学习中,价值函数(Value Function)的估计和更新过程。这通常通过训练一个神经网络(价值网络/Critic网络)来预测状态的价值 V(s)V(s) 或状态-动作对的价值 Q(s,a)Q(s,a)。最常见的训练方法是使用均方误差(Mean Squared Error, MSE)损失
价值函数 Vϕ(st) 的目标是准确估计未来累积折扣奖励。因此,训练它的方法就是让它的预测值 Vϕ(st*) 尽可能接近“真实”的累积折扣奖励 R_t。
价值损失采用的是MSE损失,最小化如下目标函数:
ℒcritic(ϕ) = 𝔼t[(Vϕ(st)−Rt)2]
其中Vϕ(st)为价值模型预测出来的回报,Rt为实际得到的回报。
Rt 是理论标签值,需要计算出来
如果使用时序差分目标,则
Rt = rt + γVϕ(st + 1)
如果使用GAE目标,则 Rt = ÂtGAE + V′ϕ(st)
1.3.3. RLHF
1.3.3.1. 构建奖励模型
收集偏好数据,对模型回答的多个数据,评估排序,不是打分
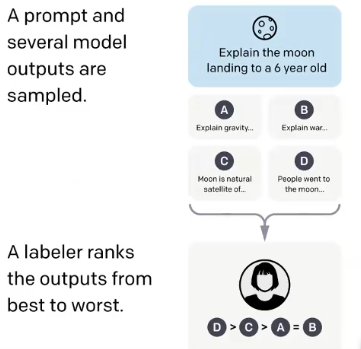
损失函数,max(做好回答- 最差回答)

只获取最后一个token的评估

使用KL散度,避免与模型的差距较大
使用PPO函数,计算历史和未来的奖励

1.3.3.2. 总体流程
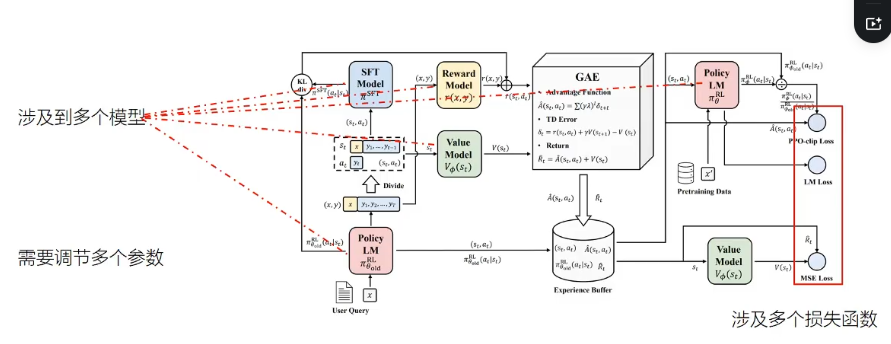
RLHF实开源链接:
https://github.com/huggingface/trlhttps://github.com/OpenRLHF/OpenRLHFhttps://github.com/hiyouga/LLaMA-Factoryhttps://github.com/WangRongsheng/awesome-LLM-resourses
1.3.4. RLAIF
模型选择结果,替换人类标记,同时需要使用双重判断
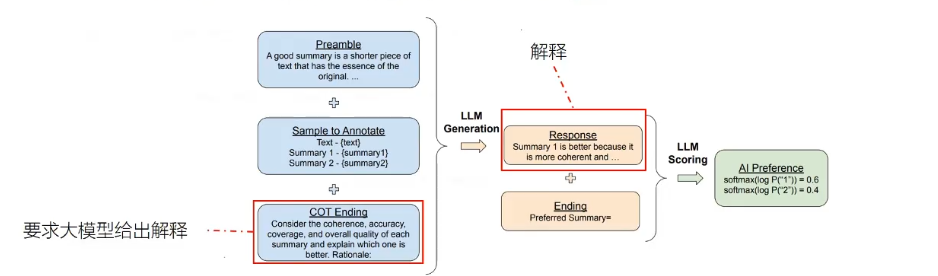
- D-RLAIF,模型直接打分,不再训练
- 常规RLAIF,先训练奖励模型
1.3.5. DPO算法(direct perference option)
由偏好学习的数据,直接用于模型的训练
目标:

损失函数:

1.3.6. SPLN(self play)
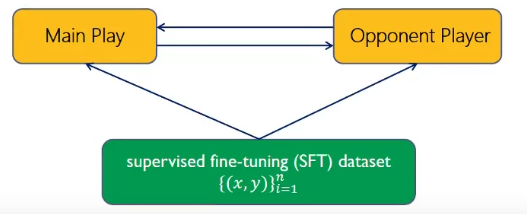
1.3.6.1. main play
区分某个回答是人类的回答

1.3.6.2. opponent play
不需要区分人类回答和LLM回答
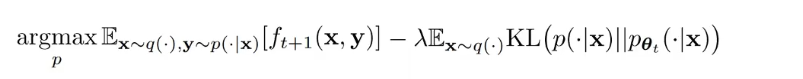
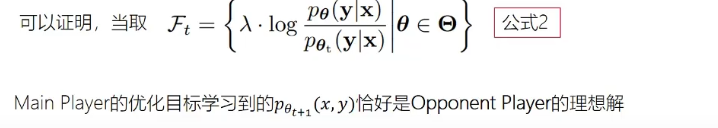
得到优化目标
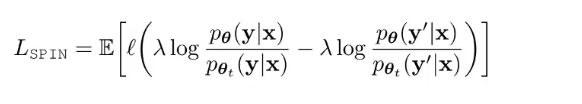
最大化生成与真实标注的信息与自己生成信息的差距
1.3.7. self-rewarding
模型给自己提供奖励,在优化回复的功能是,优化模型指令遵循与打分的能力
- 初始模型,具有基础能力
- 种子数据集,少量数据集,
- 指令微调,只有回答
- 评估微调,回答排序
模型使用种子数据集,生成新的prompt,模型自己打分,取最高分与最低分,加入数据集,用于DPO训练。
不断迭代
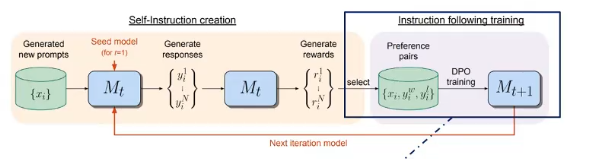
1.4. 微调
增加参数微调
- 软提示微调: 在embeding之前怎么增加soft prompt,训练优化增加的soft
prompt ,模型的参数固定
- 且不同的任务可以使用不同的soft prompt
- 适配器微调: 在模型前后增加一个层
- 软提示微调: 在embeding之前怎么增加soft prompt,训练优化增加的soft
prompt ,模型的参数固定
选择性微调
- 学习优化哪些参数,优化任务结果,使用正则化,惩罚修改较多的参数
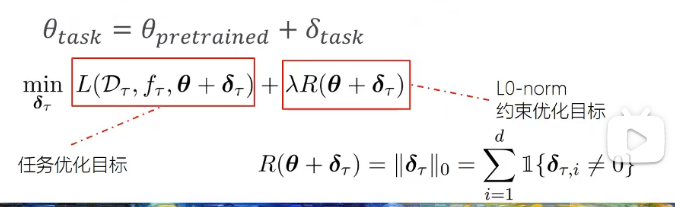
- 指定修改部分参数
- 学习优化哪些参数,优化任务结果,使用正则化,惩罚修改较多的参数
重参数微调,调整子空间参数
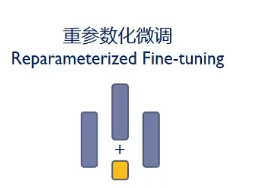
Low-Rank Adaption(LoRA),优化两个低秩矩阵,与原矩阵组合

学习模型的缩放因子
1.5. 知识蒸馏
教师模型将知识提取出来,学生模型学习其中内容
1.5.1. 基于特征的知识

1.5.1.1. 多个教师教学
1.5.2. 基于关系的知识
1.6. 模型剪枝
删除权重小于一定阈值的连接或神经元节点,获得更加稀疏的矩阵
1.6.1. 结构化剪枝
参数从起点到重点,图中有相连,则保留
2. 简短
2.1. 预训练
2.1.1. 词表化
2.1.1.1. BBPE(byte-level BPE)
单词量过大时,每一个单词一个token使用,词表空间较大
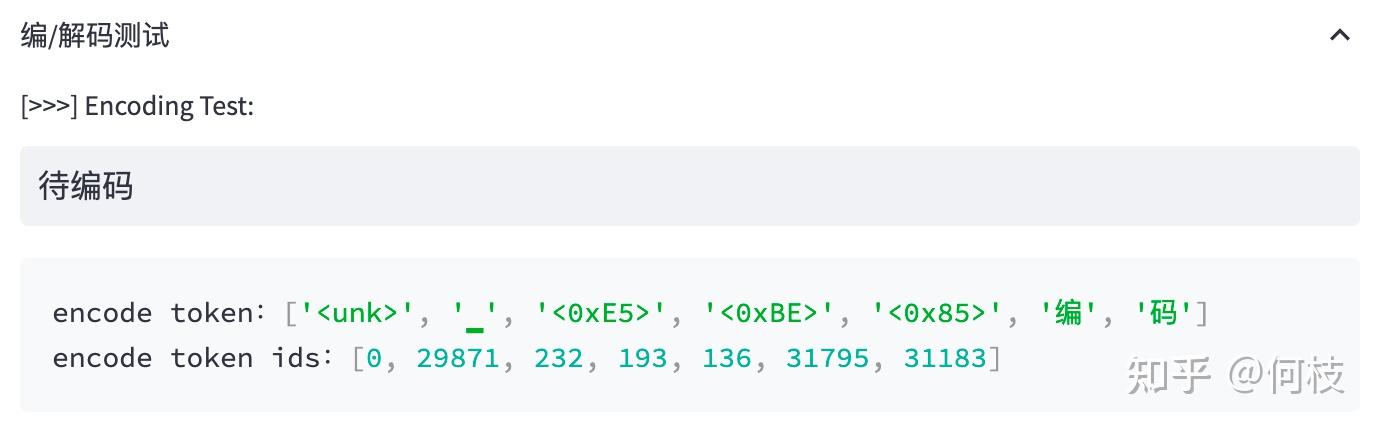
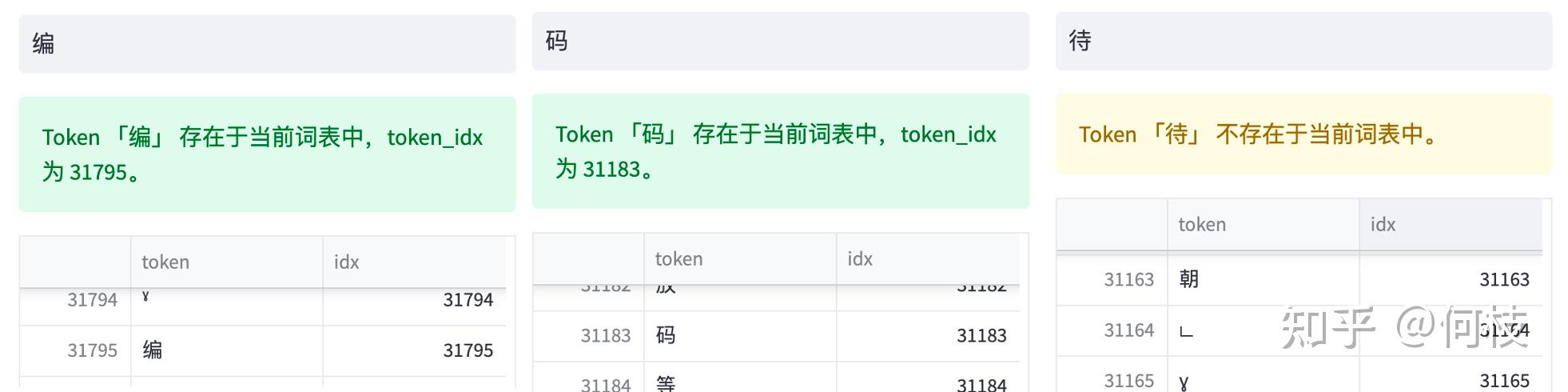
单词使用字节标识,采用unicode 编码作为最小颗粒度,将单词切割为字节token
例如,对于不存在的字节“待”,使用3个字节标识(中文在unicode编码中使用三个字节表示)
2.1.2. 模型预训练
采用无监督学习,学习输入文本的特征,学习语言语法
输入一堆文本,让模型做 Next Token Prediction 的任务,学习基础语法,初步学习。
类似与transfomer论文中的对语言的输入学习输出。
2.2. 指令微调
GPT-3只能完成续写任务,InstructGPT可以根据指令回答问题

2.2.1. 监督学习
给出指令问题,并给出答案,监督模型学习
指令: 在面试中如何回答这个问题?
- 输入:当你在车里独处时,你会想些什么?
- 输出:如果是在晚上,我通常会考虑我今天所取得的进步,如果是在早上,我会思考如何做到最好。我也会尝试练习感恩和活在当下的状态,以避免分心驾驶。
指令: 按人口对这些国家进行排名。
- 输入:巴西,中国,美国,日本,加拿大,澳大利亚
- 输出:中国,美国,巴西,日本,加拿大,澳大利亚
模型学习指令回答方式,准确的响应问题
2.3. 奖励模型
之前,模型只是简单学习了语言学习的内容,但是并不知到语言中是否正确,或者错误,这将导致预训练模型中原先「错误」或「有害」的知识没能在 SFT 数据中被纠正。
2.3.1. 利用偏序对训练奖励模型

偏序对是指:不直接为每一个样本直接打分,而是标注这些样本的好坏顺序,标准A比B好多少,而不是具体的分数。
直接打分:A句子(5分),B句子(3分) 偏序对标注:A > B
模型通过尝试最大化「好句子得分和坏句子得分之间的分差」,从而学会自动给每一个句子判分。
2.4. 强化学习(Reinforcement Learning,PPO)
进行Reward model之后,需要使用RM进化模型

