1. seqtember
1.1. deepseek 调用方法
1.1.1. API_KEY设置
设置
URL = "https://deepseek.com/chat/completions/"导入系统变量,借助
osos.getenv("变量名称", default = 默认值)
1.1.2. 请求头
authorization: Bearer API_KEY, 认证信息Content-Type: application/json, 请求内容格式,post 仅能使用Json
header = {
"authorization": f"Bearer {API_KEY}"
"Content-Type": "application/json",
}1.1.3. 请求内容payload
model: 选择模型messages: 发送的内容数组role:角色content: 内容
temperature: 设置为 0 ,模型输出更加稳定, 1,模型输出更发散
payload = {
"model": deepseek-chat,
"messages":[
{"role": "system", "content":"命令要求" },
{"role": "User", "content": "用户输入"},
{"role": ""}
]
}1.1.4. 发送请求
发送内容,使用post请求
resp = requests.post(url, header = header, payload = payload, timeout =timeout)1.1.5. response 返回内容
返回内容在resp.json()['choices'][0]['message']['content'],
提取出结果并返回

1.2. 翻译
将文本块切分成小段,指定分块大小,存放在数组中
对分段后每一段进行翻译
1.2.1. for 遍历
for i in 迭代器迭代器: 列表等
for idx, ck in enumerate(n):
for i in range(1, n) :
范围是[1,n)
1.3. day3
输入错误:
EOFerrorrequests.post发送请求时,需要包裹在try中requests发送数据,解析数据检查检查requests是否接收
except requests.exception.RequestException as e检查网络是否
resp.ok数据转换是否成
jsonexcept ValueError是否可以从数据中提取出值
`except {KeyError, IndexError, TypeError}
1.3.1. 使用超时重传发送
如果遇到rest请求错误,或者返回的resq状态码有问题,使用退避算法,进行规避n次,超过则返回
- 重复遍历
n次 - 如果遇到
请求错误,查看是否超过重复次数,没有,time.sleep一段时间后,再次运行重传 - 超过重复请求后,返回错误
1.4. day4
1.4.1. markdown 渲染
使用rich库
from rich.console import Console
from rich.markdown import Markdown
console = Console()
markdown_string = """"""
markdown = Markdown(markdown_string)
console1.4.2. 输出markdown 到word 文件中
- 首先检查文件目录存在
import os
output_dir = os.path.dirname(output_file)
if output_dir and not os.path.exist(output_dir):
os.makedirs(output_dir)- 使用
pypandoc输出
import pypandoc
"""
to: "目标格式"
format:"当前格式"
outputfile: "输出文件"
"""
pypandoc.convert_text(makedown_string, to= 'docx', format = 'markdown', outputfile = output_filepath)- 同时可以尝试检查
ImportError , Exception等错误
1.4.2.1. 直接调用pandoc 命令行工具
创建临时文件.md存储markdown内容
temp_md_file = "temp.md" with open(temp_md_file, 'w', encoding= 'utf-8') as f: f.write(m_str)使用
subprocess.run执行命令import subprocess command = ['pandoc', '-f', 'markdown', 't','doc', 'o', output_filename, temp_md_file] result = subprocess.run(command, capture_output = True, text = True, encoding = 'utf-8') if result.returncode == 0: return "转换正确"最后删除临时文件
if os.path.exist(temp_md_file): os.remove(temp_md_file)
1.5. 9.8
win11 主要文件夹路径
任务栏:C:\Users\用户名\AppData\Roaming\Microsoft\Internet Explorer\Quick Launch\User Pinned\TaskBar
开始菜单:C:\ProgramData\Microsoft\Windows\Start Menu\Programs
IE开始菜单C:\Users\用户名\AppData\Roaming\Microsoft\Internet Explorer\Quick Launch\User Pinned\StartMenu
1.6. 9.10
1.6.1. path类
from pathlib import Path
p_path = Path(路径)
## 组合路径
config_path = p_path / "config.txt"
.name ## 文件名
.suffix ## 文件后缀
.stem ## 无后缀的文件名
.parent ## 父目录
.is_absolute ## 是否为祖先路径
.revolve() ## 转换为相对路径
## 创建文件
## parents=True 会创建所有不存在的父目录
## exist_ok=True 避免目录已存在时报错
Path(路径).mkdir(exist_ok = True, parents = True)
Path(路径).touch() ## 创建空文件
p_path.write_text(str) ## 写入文件
content = file.read_text() ## 读取文件内容
1.7. 9.11 vscode 代码补全设置
开启/关闭VSCode代码提示(补全)_vscode自动提示功能怎么开-CSDN博客
1.8. 9.21 规划
1.8.1. 运筹学
- 运筹学的发展与主要内容
- 线性规划初步
- 线性规划初步
- 单纯形法Ⅱ
- LP的应用
- 对偶理论
- 对偶单纯形法、目标规划
- 修正单纯形法、列生成算法
- 运输问题
- 整数规划
- 非线性规划
- 图与网络Ⅰ
- 图与网络Ⅱ
1.8.2. 日常实习
1.8.3. 论文复现
1.9. 9.23 面试准备
1.9.1. 项目1
1.9.1.1. 子图匹配在地理位置算法中台的潜在应用场景有哪些?
- 路径规划与导航优化
- POI(兴趣点)推荐与关联
- 地理数据质量与一致性检查
1.9.1.2. 子图匹配NP问题”你是如何理解的
- 组合爆炸
- 内存消耗
解决方法:
- 优化顶点识别顺序
- 优化节点存储
1.9.1.3. 目标与衡量方面
- 剪枝效果
- 候选空间大小
- 回溯数量
1.9.1.4. 基于最小生成树(MST)的顶点匹配顺序优化方法
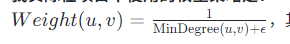
1.9.1.5. 为什么MST能够帮助尽早过滤假阳性匹配
- 构建最小生成树(MST)是为了得到一个“最优”的匹配顺序;匹配错误节点尽可能少,之后优化的结构更加精确
- 减少回溯,优先匹配那些“关键”或“脆弱”的边和顶点
具体使用的剪枝技术:
- 度数剪枝
- 标签剪枝
- 连接性剪枝
DFS匹配阶段(MS更新与剪枝)
- 连接性剪枝
- 动态更新剩余度数
- 候选集精炼
1.9.2. 项目2
1.9.2.1. 串联重复识别
一段短的DNA序列基元(称为重复单元,Repeat Unit)以头尾相连的方式重复多次,并紧密排列在一起的结构
- 疾病研究
1.9.2.2. “效率低、易漏检”,具体是什么原因导致了这些问题?
- 算法复杂度过高(效率低),字符串匹配算法限制要求精度高
- 对变异容忍度不高
1.9.2.3. 这种“周期性重复模式的高效定位”的思维方式
- 轨迹模式识别与预测
- POI周期性访问行为分析:
1.9.2.4. 评估指标
- 精确度 (Precision): TP / (TP + FP)。TP为真阳性(正确识别的TRs),FP为假阳性(误报的非TRs)。
- 召回率 (Recall): TP / (TP + FN)。FN为假阴性(漏报的真实TRs)。
- F1-score: 2 * (Precision * Recall) / (Precision + Recall)。综合衡量Precision和Recall。
1.9.2.5. MiniDBG
- MiniDBG的压缩: MiniDBG通过合并非分支节点和边来压缩图。它将任何不分叉(入度为1,出度为1)的节点序列合并成一个更长的节点(称为Unitig或Contig)。只有在序列出现分叉(入度或出度大于1)时,才创建新的节点。
- 带环边 (Cycle/Loop Edge) 的处理
- 传统DBG与循环: 传统DBG中,重复序列会形成循环(Cycles)。
- MiniDBG的压缩特性使得它能更清晰地识别出代表重复单元的“简单循环”或“自环”。
- 变异的容忍:迁移使用拥塞控制算法,在[0,2]之间TRS窗口指数型增长,[2,5]之间具有增长缓慢,10为上线,超出10后判定错误

